

Lenovo 제품별 코로나 영향 분석 (Stochastic Modeling)
들어가기전…
North Carolina State University 대학원에서 학업 중 Stochastic Process Modeling과 관련된 수업에서 진행되었던 기업협업 그룹 프로젝트이다. 나를 포함하여 인도인 1명, 한국인 1명, 노르웨이 유학생 1명으로 구성하여 총 4명의 학생이 팀을 이루어 진행하였다. 자세한 내용은 비밀유지서약서를 작성하여 다루지 못하지만, 프로젝트를 진행하며 겪었던 경험들과 분석내용을 간단하게 적어보려한다.

Lenovo는 개인용 PC 및 관련 사업을 토대로 PC산업을 이끄는 기업이다. 이 프로젝트는 North Carolina 주의 Morrisville에 위치한 미국 Lenovo 본사 데이터분석팀과 협업하여 진행하였다.
1. 프로젝트 개요 및 목적
진행기간: 2020.09.27~11.17
배경:
1
2
- 2020.03부터 미국 내 코로나 확진자 수가 증가하기 시작하여 Shut down이 진행된 상황
- Lenovo의 주요 생산시설이 우한에 있어 제품 공급이 어려운 상황
목적: 코로나가 개인용 PC 산업시장에 미치는 요인 분석 및 수요예측 (고객성향 및 지역별 특징 추출)
역할: 미팅 내용 정리 및 계획수립, 팀 커뮤니케이션 담당, 데이터 수집 및 가공, DTMC 모델링 및 Transition Matrix 설계
2. 가설
- 재택근무로 인해 Laptop보다 Desktop의 수요가 증가할 것이다.
- 실내에서 즐길 수 있는 문화(게임, OTT서비스 등)가 강세를 띄고 있어 고사양 PC 수요가 증가할 것이다.
- 주(State) 및 도시의 주 산업군에 따라 PC구매량이 달라질 것이다.
- 인구밀도가 높은 주(Metropolitan)일수록 구매량이 증가할 것이다.
3. 데이터
3.1 어디서?
- Lenovo 데이터분석팀에서 제공받은 제품별 판매현황
- 코로나 확진자 현황 (usafacts)
- 정부정책 (백악관 코로나 정책)
- Reopening 기준 (보건복지부)
3.2 판매 관련 데이터
- 2018.01 ~ 2020.09에 발생한 데이터
- 판매채널, 판매품목, 프로모션진행 여부, 지역 등
3.3 코로나 관련 데이터
- 10만명당 확진자수를 기반으로 Covid Severity 기준을 나눔 (Low - 1000명 이하, Mid - 1000~2000명, High - 2000명 초과)
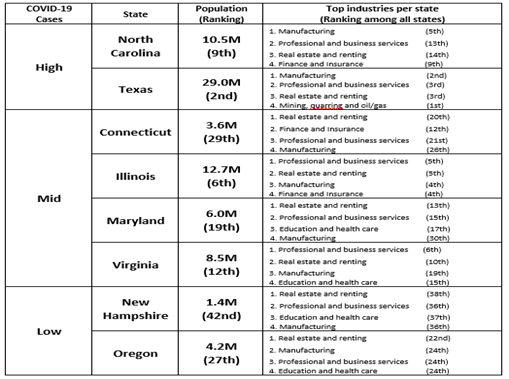
- 시/군 별 일일 확진자 수, 사망자 수 - 2020.03부터 확진자 발생
- 미국 정부의 코로나 확진 이후 Shut down 및 대응 방안
4. 모델링
4.1 회귀분석을 통한 예측모델 생성
1
2
3
- 여러가지 특성들을 조합하여 Interaction Term을 만들었고, 총 8가지 다른 모델을 선정하여 비교분석을 진행
- 성능지표로는 RMSE(Root Mean Squared Error)와 Goodness of Fit을 사용
- 최종모델로는 **Interaction term**을 포함하고 Log 변환을 사용한 모델을 선정하여 수요예측.
4.2 DTMC (Discrete Time Markov Chain)을 기반으로 진행
- 각 주(State)에 해당하는 도시로 데이터 렌더링
- 이 후, 코로나 확진자 증가율 계산 (주 단위)
- 확진자 증가율 구하여 3단계의 코로나 심각성 그룹화 (Low, Mid, High - 주(State)을 나눈 기준과 다름)
- 주간 코로나 현황 심각성에 따라 transition matrix 생성 및 각 단계별 Steady State Probability 계산
위의 얻은 결과값을 토대로 제품 및 지역별 예상 수요값을 계산하였다. 계산식은 다음과 같다.
\[(회귀분석 최종모델의 수요예측 값) X (Steady State Probability) = 제품과 지역 별 예상 수요 값\]5. 결론
5.1 솔루션 내용
- 수요예측 제공: Laptop과 Desktop 두가지 카테고리를 주 정책, 사회적 거리두기 단계, 인구밀도, 주/도시별, 용도 등에 따라 예상 수요 증감율을 토대로 수요예측 제공
- 데이터 수집에 대한 개선점 제공: 추후 개선점을 시행하기 위해 필요한 데이터 리스트형태로 제공 (프로모션정보, 판매채널 등)
5.2 한계점 및 아쉬운 점
- 회귀모델만을 사용하여 진행했던 점이 아쉬웠다. 다른 머신러닝 모델 (Lasso, XGBoost, LightGBM 등), 시계열 및 딥러닝 모델인 LSTM을 사용하여 예측을 견고하게 하는 것이 필요하다.
- 확진자 증가율에 따른 그룹화를 진행할 때, 임의적으로 기준을 맞추어 Transition Matrix가 만들어졌기에 근거가 부족하다. 총 5개의 다른 기준을 통해서 그룹화를 진행한 결과 데이터의 불균형이 가장 적은 기준을 가지고 진행하여 해결하고자 했다.
- 각 주마다 시행하는 정책이 통일성이 있지 않았다. 사회적 거리두기 단계와 기준 또한 달라서 정책의 강도를 임의적으로 맞추어야 했다.
- 프로모션의 시행여부 뿐만아니라 상세내용(집행시기, 세일 %, 시행채널 등)을 제공받지 못하여 해당 특성의 영향도를 측정하기 어려웠다.