
나의 첫 데이터분석 프로젝트: 재고과잉 20% 줄이기!
이 프로젝트는 회사와 학교와 학생팀으로 이루어져 기밀서약계약을 하고 진행한 관계로 자세하게 다루지는 못하지만 어떻게 진행을 했고 어떤 어려움이 있었으며 어떻게 극복했는지 그리고 전체적으로 진행하면서 배웠던 점과 아쉬운 점을 서술하기에 깊게 이해하기에 부족할 수 있을 것 같다.
프로젝트는 나를 포함한 3명의 학생들 (나, 중국계 미국인, 그리고 미국인), HyVee본사의 데이터 분석팀 2명과 학교 교수님으로 이루어져서 진행했다.
협업사(Company): Hy-Vee
![]()
Hy-Vee는 미국 중서부에 위치함 슈퍼마켓 체인으로서 총 245개의 지점을 가지고 있으며 주로 아이오와, 일리노이, 캔자스, 미네소타, 미주리, 네바다, 사우스 다코타, 그리고 위스콘신에 비즈니스를 운영중이다. 신선도를 무기로 타기업인 월마트나 Sam’s Club 등과 경쟁하는 업체이다.
1. 데이터
Hy-Vee는 총 두개의 유통센터(Distribution Center)가 Chariton과 Cherokee에 위치해 있으며 제품의 카테고리에 따라서 저장되는 곳이 달라진다.
전반적으로 General Merchandise (GM), Health Beauty Care (HBC), Grocery, 그리고 Frozen으로 총 4가지의 카테고리를 가지고 있다.

주어진 데이터는 csv형태로 3년동안에 저장한 모든 리테일정보를 포함하고 있다. 3개의 Chariton센터의 데이터, 2개의 Cherokee센터의 데이터, 카테고리를 설명해주는 데이터, 광고 및 계절별 프로모션 정보로 총 8개가 주어졌다.
2. 프로젝트 과정
전체적인 프로젝트 과정은 아래 이미지와 같이 총 5단계로 나뉘어져 있다. 프로젝트를 약 4개월간 학교와 회사 데이터분석팀과 함께 작업하면서 아쉬웠던점이 정말 많았다. 그 부분은 나중에 다룰 것이다.

1) 목표수립(Objective)
프로젝트를 설계할때 가장 중요하며 핵심적인 부분인 목표수립으로 HyVee측에서 요구했던 부분은 “Reduce the overall inventory overstock by 20%”이였다. 즉, 전체 재고과잉을 데이터 분석을 통해서 20%를 줄이는게 이 프로젝트의 목적이였다.
2) 데이터 탐구 및 정제(Explore Data Analysis)
1) 각 feature들을 이해하고 프로젝트와 관련이 있는 데이터들만 추린다.
2) 각 feature별 선형성 및 분포도를 scatter plot과 히스토그램으로 확인한다.
3) Correlation을 통해 의존도가 높은 feature들을 추출한다.
4) 불필요한 데이터는 제거한다. 시간, ID등 프로젝트의 필요없는 데이터
3) 분석모형 수립(Model Selection)
초창기 계획은 Association Rule과 Tree계열인 Random Forest를 계획하고 있었으나 너무나도 많은 vendor들과 vendor마다 파는 제품이 정말 많아서 Association Rule을 통한 관계성분석이 좋을 것이라 판단하여 진행을 했다.
4) 데이터 가공(Feature Engineering)
맨 처음 Correlation을 통해서 관계성이 높은 feature그룹을 묶고 토의 끝에 대표적인 데이터나 가공을 통해서 데이터의 column 수를 줄여나가는 작업을 진행했다.
그 이후에 가장 중요한 Target값인 Overstock을 회사와 토의하여 정의하고 주어진 데이터로 공식을 만들어 적용했다. 공식과 관련 feature들의 내용을 상세적으로 설명할 수는 없지만 공식은 이와 같다. “주간 재고과잉의 수”를 타켓값으로 잡고 재고상황을 파악했다.
| 정의 | 공식 |
|---|---|
| 재고를 감당하는 주간 (Number of Weeks Currently on Hand) |
\(\cfrac{\displaystyle 재고(On Hand Balance)}{\displaystyle 계절별 주간 재고예측(Seasonalized Weekly Forecast)}\) |
| 재고를 허용할 수 있는 주간 (Number of Acceptable Weeks on Hand) |
납품소요시간 + 추가 허용시간 (Vendor Lead Time + Bonus Weeks) |
| 재고과잉이 벌어지는 주간 (Number of Weeks Overstocked) |
현 재고를 감당하는 주간 - 재고를 감당할 수 있는 주간 (Number of Weeks Currently on Hand - Number of Acceptable Weeks on Hand) |
| 주간 재고과잉의 수 (Number of Units Weekly Overstocked) |
재고과잉이 벌어지는 주간 * 계절별 주간 재고 예측 (Number of Weeks Overstocked * Seasonalized Weekly Fcst) |
5) 모델링(Modeling)
Association Rule을 사용하여 Overstock이 있는 품목중에서 가장 잘 나오는 Set를 구하였다.
Support: X와 Y가 얼마나 자주 나오는지를 측정 P(X)
| Confidence: 조건부확률로 X가 발생했을 때 Y가 발생할 확률, P(Y | X) |
Lift: X와 Y가 같이 나오는 비율을 X의 비율와 Y의 비율을 곱한 값을 나눈 값으로 값이 클수록 X와 Y는 자주 발생한다는 뜻. 판단의 기준으로는,
- lift > 1 X와 Y는 연관성이 크다
- lift = 1 X와 Y는 독립적
- lift < 1 X와 Y는 연관성이 적다
ex) Lift = 2.5, 다른 경우의 수보다 2.5배 더 자주 발생한다.
위 결과값들을 토대로 일일이 Lift값이 큰 set들을 엑셀로 정리하고 그의 따른 Overstock의 비율을 구했다. 자세한 내용은 다루지 못하지만 각 분야별 overstock proportion을 구하고 큼지막한 부분들을 추려서 정리하였다.
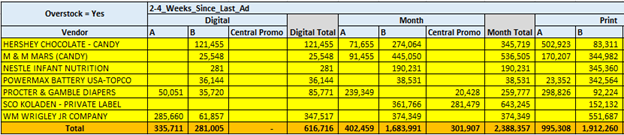
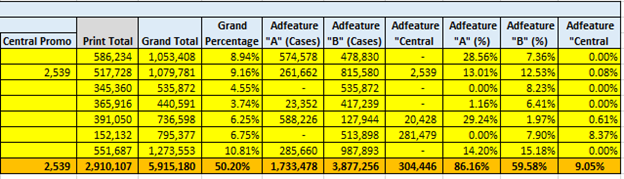
6) 결과(Reporting)
위의 결과값을 통해서 Overstock 전체의 18.2%의 해당하는 Rule을 추출하였고, 그와 관련된 Recommendation을 작성하였다. 대체적으로는 공급자 및 해당 제품의 관리자에게 정보를 알려주어 특정한 아이템과 세트들에 물량을 줄이는 방향으로 작성하였다. 또한 그에 파생되는 경제적 이점을 계산하기 위에 아래의 공식을 사용하였다.
$Expected Saved Cost = \cfrac{\displaystyle 줄인 물량(# of Overstock Cases Prevented) * 줄인 물량의 평균값(Average Cost Per Prevented Cases) * 0.1}{52}$
4. 아쉬운 점과 개선할 수 있는 점
대체적으로 배운점도 많았고 느낀점도 많았다. 이 프로젝트를 진행하면서 실무에서 분석프로젝트를 진행할때 겪을 수 있던 문제정의, 데이터의 이해, 데이터의 정제 및 가공, 커뮤니케이션의 어려움 등 값진 경험을 했다.아쉬운점은 굉장히 많지만 크게 네가지가 있다.
첫째, R 프로그래밍과 데이터분석의 미숙함에서 오는 비효율성이다. 분석하면서 많은 시간을 리서치하고 적용하는 시간을 보냈지만 그 안에서 프로그래밍적인 오류들이 굉장히 많아서 중간중간 데이터 및 작업물도 날려버리는 사태가 발생했다. 그래서 이후에 리뷰를 할때 잘 알아보기 힘들정도로 난잡하게 되어있는 점이 굉장히 아쉬웠다. 중간중간 일지처럼 기록을 했더라면 혹은 Markdown을 사용할 줄 알았다면 더욱 수월할 거라는 생각에 그 이후에 정리하려는 습관을 들이려고 노력했다.
둘째, 회사측에서 Financial Effect와 관련하여 정확한 지침을 얻을 수 없었다. 마지막 단계에서 리포팅을 할때 가장 중요한 부분인 Financial effect를 제공받지 못하여 이 프로젝트가 어느정도 효용성이 있는지를 파악하지 못했던 점이 가장 아쉬웠다. 물론 나중에 피상적으로나마 제공받은 정보로 계산을 하였지만 디테일하게 못들어간 점이 아쉬웠다.
셋째, 더 적절할 수 있던 FP-Growth 알고리즘의 존재여부를 몰랐다. 프로젝트를 마치고 리뷰를 할때 “시계열분석이 필요하지 않을까”라는 생각을 많이 가지고 있었지만 1)item set가 굉장히 방대했으며 2) 나온 결과값인 Rule들이 굉장히 많았기에 시계열분석은 상관없다는 생각이 든다. 그 이후에 다른방법을 찾던 중 최근에 FP-Growth 알고리즘이 Item set가 많을 때 연관규칙(Association Rule)을 개선할 수 있다는 것을 알았다. 이 알고리즘과 관련하여 나중에 공부하고 포스팅하여 정리를 해봐야겠다.
넷째, 프로젝트 결과 및 알고리즘을 실무에 적용시키는 법이 어려웠다. 실제적으로 회사에서는 분석이후의 결과들을 실제 프로세스에 어떻게 적용하는지 경험하지 못해서 많이 아쉬웠다. 단순히 리포팅에서만 끝나는 것이 아닌 그 이후에 자동화를 시키며 꾸준한 피드백과 알고리즘의 업데이트 등 총괄적인 과정이 궁금하다.
대체적으로 배운점도 많았고 느낀점도 많았다. 이 프로젝트를 진행하면서 실무에서 분석프로젝트를 진행할때 겪을 수 있던 문제정의, 데이터의 이해, 데이터의 정제 및 가공, 커뮤니케이션의 어려움 등 값진 경험을 했다.